Getting Started on Wulver¶
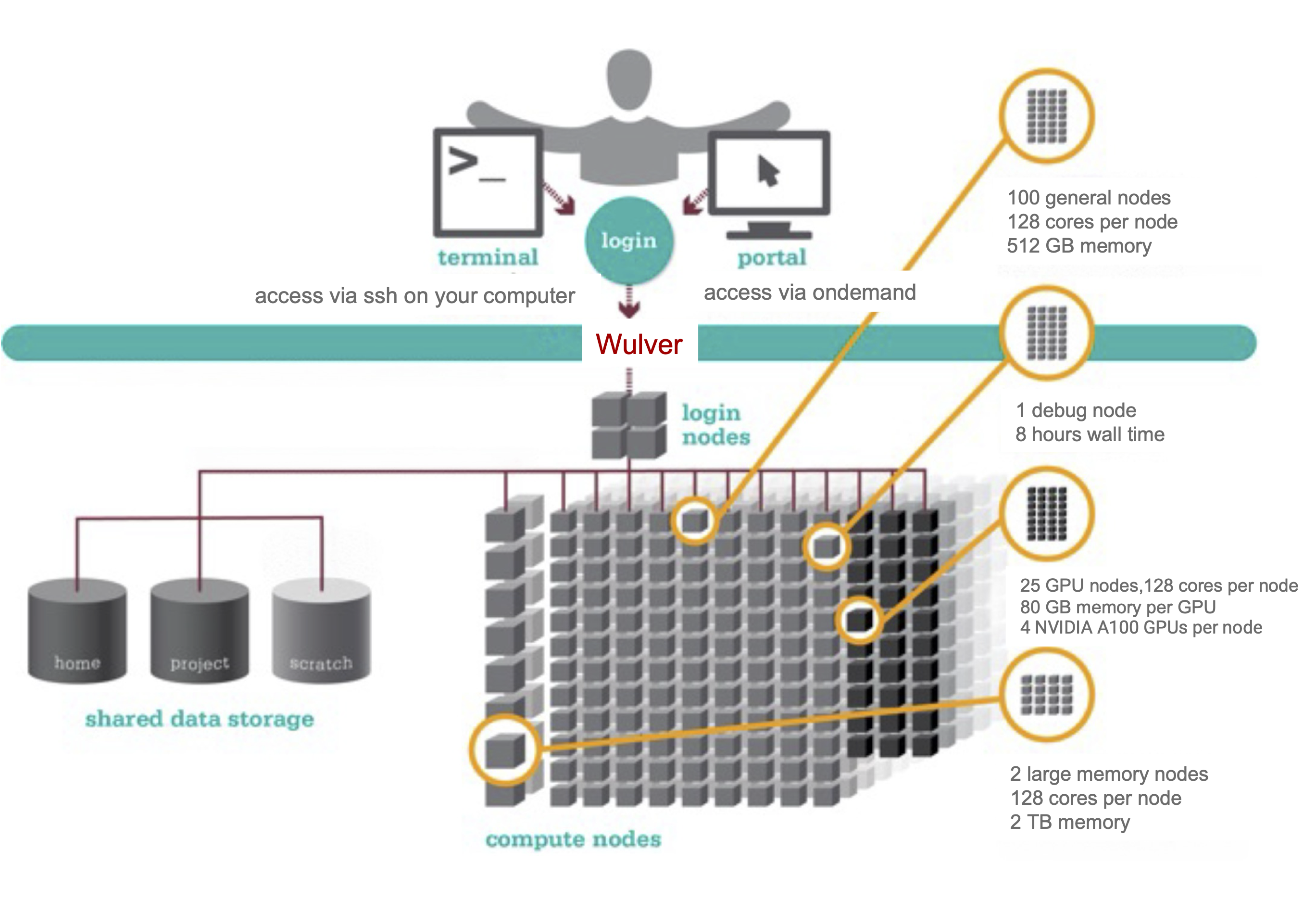
Wulver is a high performance computing (HPC) cluster – a collection of computers and data storage connected with high-speed low-latency networks. We refer to individual computers in this network as nodes. Wulver is only accessible to researchers remotely; your gateways to the cluster are the login nodes. From these nodes, you can view and edit files and dispatch jobs to computers configured for computation, called compute nodes. The tool we use to manage these jobs is called a job scheduler. All compute nodes on a cluster mount several shared filesystems; a file server or set of servers store files on a large array of disks. This allows your jobs to access and edit your data from any compute node.
Being a Good HPC Citizen¶
While using HPC resources, here are some important things to remember:
- Do not run jobs or computation on a login node, instead submit jobs to compute nodes. You should be using
sbatch,srun, or OnDemand to run your jobs. - Never give your password to anyone else.
- Do not run larger numbers of very short (less than a minute) jobs Use of the clusters is also governed by our official guidelines. Violating the guidelines might result in having your access to Wulver revoked, but more often the result is your jobs will run painfully slower.
Remote Access¶
All users access the Wulver cluster remotely, either through ssh or a browser using the Open OnDemand portal. See these detailed login instructions. NB: If you want to access the clusters from outside NJIT’s network, you must use the VPN.
Schedule a Job¶
On our cluster, you control your jobs using a job scheduling system called Slurm that allocates and manages compute resources for you. You can submit your jobs in one of two ways. For testing and small jobs, you may want to run a job interactively. This way you can directly interact with the compute node(s) in real time. The other way, which is the preferred way for multiple jobs or long-running jobs, involves writing your job commands in a script and submitting that to the job scheduler. Please see our Running Jobs or review our training materials for more details.
Use Software¶
To best serve the diverse needs of all our researchers, we use software modules to make multiple versions of popular software available. Modules allow you to swap between different applications and versions of those applications. The software can be loaded via module load command. You see the following modules are loaded once you log in to the Wulver. Use the module li command to see the modules.
1) easybuild 2) slurm/wulver 3) null
Shared Filesystems¶
A critical component of Wulver is its shared filesystem, which facilitates the efficient storage, retrieval, and sharing of data among the various compute nodes. It enables multiple users and applications to read from and write to a common storage pool, ensuring data consistency and accessibility across the entire system. See Wulver Filesystems for a different type of shared filesystems.
Transfer Your Files¶
As part of setting up and running jobs and collecting results, you will want to copy files between your computer and the clusters. We have a few options, and the best for each situation usually depends on the size and number of files you would like to transfer. For most situations, uploading a small number of smaller files through Open OnDemand's upload interface is the best option. This can be done directly through the file viewer interface by clicking the Upload button and dragging and dropping your files into the upload window. Check the Ondemand file transfer for more details. For more information on other upload methods, see our transferring data instructions.
Workshop and Training Videos¶
Each semester, we host webinars and training sessions. Please check the list of events and register from HPC Events. You can also check the recordings of previously hosted webinars at HPC Training.
Linux¶
Our cluster runs Red Hat Enterprise Linux 8, utilizing the bash (or zsh set via https://myucid.njit.edu) command line interface (CLI). A basic familiarity with Linux commands is required for interacting with the clusters. We have a list of commonly used commands here. We periodically run an Intro to Linux Training to get you started, see our Events for upcoming training. There are also many excellent beginner tutorials available for free online, including the following:
In the table below, you can find the basic linux commands required to use the cluster. For more details on linux commands, please see the Linux commands cheat sheets.
| Linux Commands | Description |
|---|---|
cd [directory] |
Change directory |
cd .. |
Change to one directory up |
mkdir [directory] |
create a directory |
mkdir -p [directory] |
create directories as necessary, if the directories exist, no error is specified |
pwd |
Print current working directory |
ls |
lists directory contents of files and directories |
ls -ltra |
all the files in long format with the newest one at the bottom |
cp /path/to/source/file1 /path/to/destination/file2 |
Copy files from source to destination |
cp –r /path/to/source/dir1 /path/to/destination/dir2 |
Copy directory from source to destination |
mv /source/file1 /source/file2 |
move directories or files and rename them |
cat filename1 |
display the content of text files |
rm -rf /path/to/dir |
used to delete files and directories |
Get Help¶
If you have additional questions, please email us at hpc@njit.edu. If you are having a problem with sbatch or srun, please include the following information:
- Job ID#(s)
- Error messages
- Command used to submit the job(s)
- Path(s) to scripts called by the submission command
- Path(s) to output files from your jobs
Here are some tips to get help faster:
- The fastest way to get help is by sending an email to HPC@NJIT.EDU, this is routed right to us at ARCS HPC and will be answered by the most knowledgeable team member based on your question.
- Never reply to an earlier HPC email incident as the ticketing system does not make a new ticket when you respond to an already closed ticket.